

One of the core principles of any effective Business Intelligence (BI) practice is ensuring that analytical outputs are timely, accurate, and fit for purpose. When those foundations aren’t in place, organisations quickly fall into the familiar trap of “garbage in, garbage out”, resulting in misleading dashboards, inconsistent metrics, and a lack of trust in reporting.
As organisations consider leveraging AI, it’s important to recognise that AI dramatically raises the stakes of data quality and structure.
While poor data might result in a confusing report or an incorrect KPI, poor data fed into AI systems can produce confident, persuasive, and entirely incorrect conclusions at scale. In other words, AI doesn’t just inherit your data problems; it amplifies them.
This is where AI data readiness comes in, and why organisations with mature BI practices are far better positioned to succeed with AI than those starting from raw data alone.
What Is AI Data Readiness?
AI data readiness refers to the state of an organisation’s data being structured, governed, contextualised, accessible and trusted enough to be safely and effectively used by AI tools.
AI data readiness means an organisation’s data is organised in a way that makes it structured (arranged in a clear format), governed (managed by explicit rules and oversight), contextualised (linked to relevant business meanings and uses), accessible (easy to obtain and use by those who are permitted), and trusted (having quality and consistency that users rely on) enough to be safely and effectively used by AI tools.
Put simply: AI-ready data is data that is already fit for decision-making.
This isn’t a new discipline — it’s an extension of good BI and analytics practices. The difference is that AI requires these principles to be applied more rigorously, not less.
AI-ready data should:
- Represent a single, agreed version of the truth
- Be well-defined and consistently structured
- Carry business context, not just raw values
- Be governed, so AI only accesses what it should
Without this, AI models can infer meaning where none exists — leading to confident but incorrect outputs, bias, and unreliable results.
Why Raw Data and AI Don’t Mix
A common misconception is that AI performs best when given more data — especially raw data stored in a data lake.
In reality, this is one of the fastest ways to generate unreliable results.
Raw data:
- Often contains duplicates, gaps, and conflicting values
- Lacks business definitions and metric logic
- Includes fields that look meaningful but aren’t
- Mixes operational, historical, and incomplete records
When a human analyst works with this data, they apply judgment, experience, and business rules to interpret it correctly. AI does not do this unless those rules are explicitly embedded in the data layer.
Giving AI unrestricted access to raw tables is effectively asking it to guess the meaning of your business.
AI Without BI: Lessons from Real-World Deployments
Several high-profile AI initiatives have failed not because the technology was flawed, but because the underlying data lacked governance, context, and a clear semantic layer.
Zillow, for example, relied on AI models to automate home pricing decisions using large volumes of volatile market data, without sufficient controls to ensure consistency, regional context, or reconciliation against trusted financial metrics. The result was confident but incorrect pricing at scale, leading to significant financial losses.
Similarly, Amazon abandoned an AI-driven recruitment tool after it learned biased patterns from historical hiring data (including a bias against female candidates) that had never been normalised, contextualised, or governed through explicit business rules.
In both cases, a strong BI layer could have constrained AI behaviour, surfaced risks earlier, and prevented AI from inferring unintended meaning. These examples reinforce a crucial point: AI amplifies your data estate's strengths and weaknesses, and, without BI discipline, scales the weaknesses first.
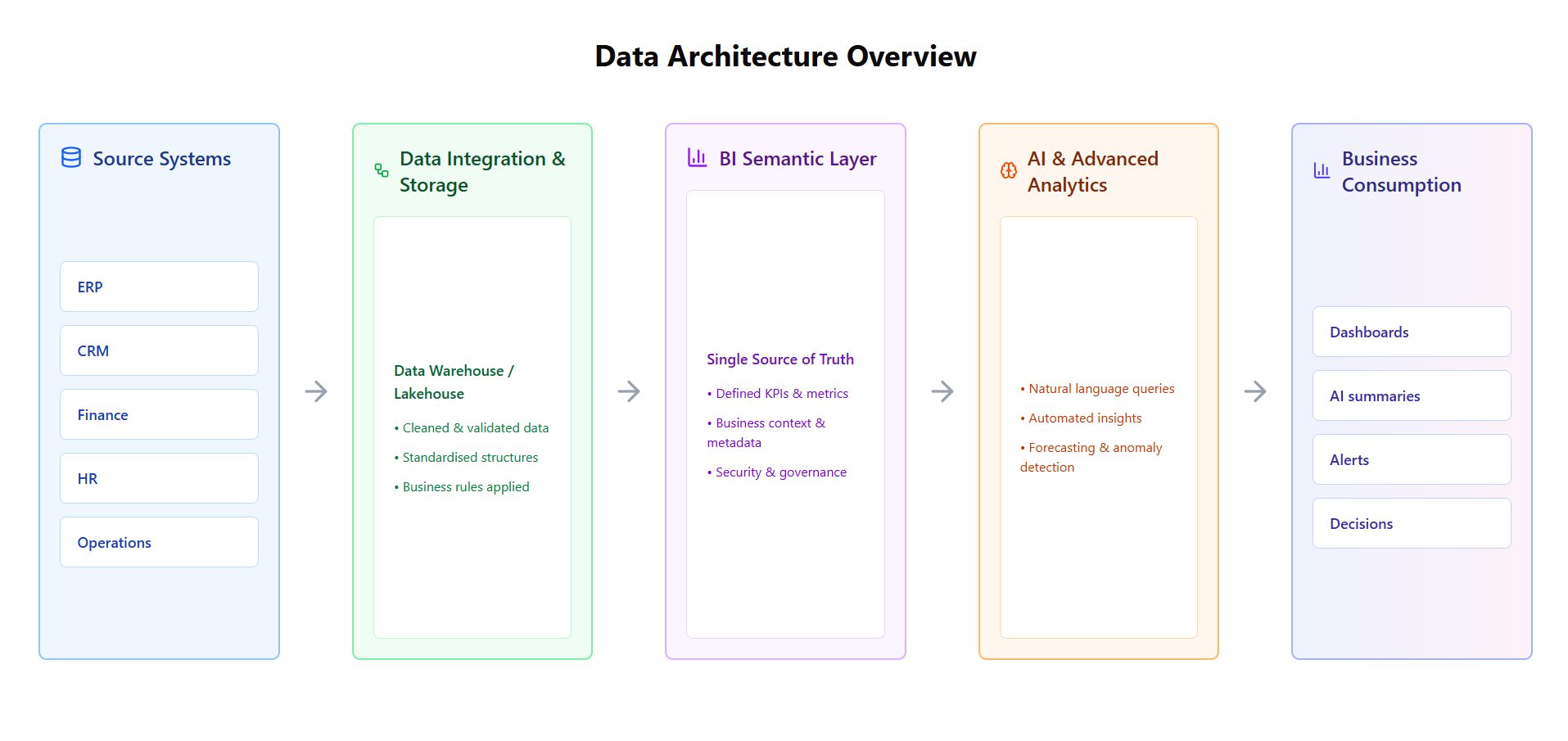
The Direct Link Between BI and AI Readiness
Organisations that already invest in BI often don’t realise how close they are to being AI-ready.
A well-designed BI environment typically includes:
- Curated semantic models
- Agreed on business definitions for KPIs
- Data quality checks and validation rules
- Controlled access to trusted datasets
- Clear lineage from source to report
These same components are exactly what AI tools need to function reliably.
In fact, AI performs best when it operates on top of the same curated datasets used for reporting, rather than bypassing them.
Think of AI as a new way to interact with your BI layer, not a replacement for it.
The most successful AI analytics implementations use a layered approach, with AI sitting on top of an established BI foundation.
Practical Examples: AI in the BI Space
Natural Language Queries
When users ask questions like “Why did revenue drop last quarter?”, AI must understand:
- What “revenue” means
- Which version of the metric to use
- The relevant time period and filters
If those definitions already exist in your BI model, AI can answer confidently and correctly. If not, it will invent assumptions.
Automated Insights and Narratives
AI-generated commentary relies on consistent measures and hierarchies. If totals don’t reconcile or dimensions behave unpredictably, automated explanations quickly fall apart.
Forecasting and Anomaly Detection
AI can identify patterns and outliers — but only if historical data is complete, comparable, and stable. Poorly governed data produces false signals that look statistically valid but are operationally meaningless.
Key Components of AI-Ready Data
Quality and Accuracy
AI cannot correct incorrect data. It will confidently repeat it.
Data must be:
- Complete and validated
- Consistent across systems
- Free from known bias and duplication
Context and Structure
AI needs metadata just as much as humans do:
- Clear column definitions
- Consistent naming conventions
- Logical relationships between entities
Without this, AI treats fields as interchangeable numbers.
Accessibility and Control
Not all data should be discoverable by AI.
AI should only interact with approved, trusted datasets — typically the same ones exposed to business users via BI tools.
Governance and Trust
Strong governance ensures:
- Privacy and security are maintained
- Regulatory requirements are met
- Outputs can be explained and defended
Trust in AI outcomes starts with trust in the data underneath them.
The Takeaway
If you already have a well-governed BI environment with trusted reporting and clearly defined metrics, you’re most of the way there.
Before introducing AI tools into your analytics ecosystem, the most important question isn’t “Which AI platform should we use?”, it’s “Is our data ready to be trusted at scale?”
If the answer is yes, AI becomes a powerful extension of your BI capability.
If the answer is no, the smartest move is to address those gaps first, before letting AI loose on your data.



